Journey to the Center of Kube: Sink
Kube is a client that allows you to work offline, so you can work no matter whether your train just entered a tunnel, you’re on board of a plane or you’re just too lazy to get up and ask for the free wifi password. One implication of this is that we have to deal with fair amounts of data.
Email tends to accumulate quickly, and it’s not uncommon to have mail folders that have somewhere between 40’000 and 200’000 emails in them, so we have to figure out a way to deal with that. At the core of Kube we therefore have Sink; the data-access and synchronization system.
Sink is responsible for efficiently providing all necessary data for Kube to display, and for acquiring that data in the first place. Here’s how it fulfills those requirements.
Not just efficient but also effective
Although we’re dealing with large amounts of data, Kube really shouldn’t ever get in your way, and that means no waiting for Kube loading stuff.
It’s of course possible to optimize the components that load and present the data to be very efficient towards that end, however, that is a very costly process. Optimization takes a lot of time and effort and often works against the maintainability and simplicity of the overall system.
Another approach is to be effective instead, and that means to just do the work that we really need to do, and thus ending up in a better place even if not as optimized for top notch efficiency.
For the loading of a list of mails that means that we just load the data that is actually necessary. Even though you may have 40’000 mails in your Inbox, we can’t actually fit more than, say, 10 on the screen, so why not just load that? We know the order of the mails (sorted by date), so we can simply query for the subset we’re interested in, and fetch more as you scroll down in the list.
This approach can be taken to all sorts of data, but it has some implications. For one we need to prepare our store in a way that we can actually query for the data we want. This means building the relevant indexes as we store the data, which has the added benefit that we also only have to do that work once, and from then on profit every time we have to read the data.
Persistence
To deal with the data we need a persistence solution that allows us to both access and write the data fast. You don’t want to wait longer than necessary to pull that mail folder offline, nor do you want to wait for Kube loading a bunch of mails from disk. And ideally we’ll do that without requiring you to deal with external database processes that need to be managed and configured, keeping the complexity of the overall system low.
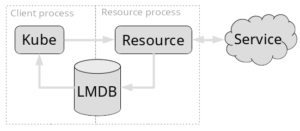 The solution that fit our bill was LMDB, the Lightning Memory-Mapped Database. LMDB is a small key-value store that is fast while writing, and really fast while reading. It’s embeddable, meaning we can load data directly in-process and supports single-writer/multi-reader semantics, allowing us to write with one process and read with another. An important property for us because we use backend processes to deal with the synchronization with the server.
The solution that fit our bill was LMDB, the Lightning Memory-Mapped Database. LMDB is a small key-value store that is fast while writing, and really fast while reading. It’s embeddable, meaning we can load data directly in-process and supports single-writer/multi-reader semantics, allowing us to write with one process and read with another. An important property for us because we use backend processes to deal with the synchronization with the server.
Synchronization
Something needs to acquire the data and know how to synchronize with the server. In Sink those backends are called Resources. A Resource can for instance implement the IMAP protocol to provide access for all your mails. This backend plugin-system abstracts and contains the service specific bits, so Kube doesn’t have to concern itself with the 15 different ways to get to email out there. Either an already existing plugin supports a protocol that we need, or we can just write a new one without touching Kube.
While not necessary by design, separating those Resources into separate processes has some benefits; We get parallelism. Certain synchronization tasks can be resource intensive, and a separate process ensures we don’t impact the performance of Kube directly, respectively we let the OS manage it. Further we get isolation so resources can crash without impacting Kube. While this shouldn’t be a huge concern as long as all resources are of adequate quality, it’s the resources that are exposed to whatever comes in over the internet, so they are in many ways the most fragile parts.
Summary
I hope this post gave you some insight on some of the technical aspects of Kube and the approach we’re taking on the problems we face. It’s of course just scratching the surface, so I’ll hope to complete that picture bit by bit.
If you want to know more about Kube’s design and inner working, keep an eye on this blog for future updates.
And if you just want to give it a shot for yourself, head over to Kube for Kolab Now.
For more info about Kube, please head over to About Kube.