For the sake of transparency we used to report on our interactions with authorities every year. Unfortunately we have missed a few of those reports. Some users missed such updates, and , not only for those users, but also according to our terms of service, and for the sake of transparency, we want to restart this good routine. This post is the transparency reporting for the year 2025.
Jingle & Join: The Kolab Now Referral is ON (fire)
It is almost this time of the year again – “one horse open sleigh” bells start to ring and the festive mood fills the air.
As always it is also the season of giving and this year giving privacy pays off 🙂

How it works
Share your personal Jingle&Join Referral Code with a friend and earn CHF 20 once your person/persons topped up their wallet with CHF 10 – offering 50% discount for the first 3 months of usage.*
Step by step
- Navigate to your wallet
- Find your personal Jingle&Join Referral Code (link)/ QR-Code
- Copy that link and send it out to your friends, offering them 50% discount for the first 3 months of usage
- For every successful sign-up with a topped up wallet of min. CHF 10, you earn CHF 20 (Kolab Now will add this to your wallet)
If you are still looking for a meaningful gesture during this Jingle bells season – Jingle&Join Referral is ON.
Spread joy – not data
We wish everyone lovely pre-Christmas days.
*The Jingle&Join Referral Program will be active until 31.01.2025
Stay in Sync as a Family with Kolab Now
Running a family is a team effort! Between school schedules, grocery lists, birthdays, chores or appointments there is always something to remember – and to share.
A lot of parents choose big-tech apps for coordination, but with Kolab Now you can keep your family organized and your data private. Here is how you can use Kolab Now features like calendars, tasks and notes to stay perfectly in sync.
Incident report: IMAP client service temporarily unstable..
Last night at 21:50 UTC a large number of client connections hit Kolab Now, which resulted in the IMAP client servers (‘imap.kolabnow.com’) running out of memory. Staff was noted about the issue at 06:00 UTC, and immediately raised the amount of memory for these servers, which brought the issue to an end.
During these ~8 hours users of IMAP clients had issues with unstable connections; some might even have been completely unable to connect.
Mail transport was not impacted. all mails were streaming in and out as they should, and also the webclient (‘https://kolabnow.com/apps’) worked well during the period.
The issue was the unusually large number of incoming client connections. To mitigate the situation and avoid similar issues, the staff has enlarged the memory size on the servers in question, and are now working to improve the monitoring of the service.
We regret the incident and apologize for any inconvenience that this may have caused.
Synchronization problems with the latest update of the Gmail app on Android
The latest update on Android unfortunately broke the synchronization via ActiveSync, provided by the Gmail app. This affects not only Email, but also the synchronization of Contacts and Calendars.
If an affected version of the Gmail app is installed, all folders will be continuously re-synchronized from scratch, which results in the temporary availability of the contents, and a continuous stream of notifications for new messages which are downloaded over and over again.
This is a regression of the Gmail app, and unfortunately is not fixable on the server-side.
The following app versions are known to be affected:
– 2025.11.02.828149635.Release
– 2025.10.13.822206885.Release
If you can avoid updating the Gmail app, we strongly recommend that.
To downgrade, the following steps are possible, at your own risk. Please also note that this will remove all configured accounts.
– Uninstall the Gmail app from the PlayStore. This will downgrade the version to the one provided with the OS. You can use this version of Gmail if you like.
– The latest unaffected version is 2025.09.15.810231445.Release, to which you can upgrade after downgrading first. Please note that it is not possible to directly downgrade to this version.
WARNING: The following link is from an external source, and we cannot take responsibility for the content provided. Use at your own risk.
You can find the .apk for latest good version of the Gmail app here https://gmail.en.uptodown.com/android/download/1111199927
Incident: Service temporarily unavailable
Kolabnow is currently experiencing a service interruption due to a spontaneous hypervisor reboot. We apologize for the inconvenience while we investigate the issue. We will update this blogpost as soon as more information is available.
2025-07-30 @ 22:50 UTC: This issue was triggered by one of our hypervisors spontaneously rebooting at approximately 19:45 UTC, and manual intervention was required to get all services to recover. Most services have been restored, the Operations team is working through remaining issues. Users can login and use the facilities. Some delays in email delivery are expected, no data was lost.
2025-07-30 @ 23:39 UTC: The incident has been resolved.
Changes to Kolabnow password expiry policy
Today we deploy a change to the Kolab Now password expiry policy, which will affect you only if you:
– have enabled an expiry policy in your profile
– your password expired according to that policy
If both of these conditions are the place, you will be prompted to change your password when you login in to the cockpit with your correct, but expiring, password.
ActiveSync changes to help with stuck devices
ActiveSync is the protocol used to synchronize various mobile devices, desktop clients, as well as Outlook.
While mobile device synchronization works mostly without issues via this protocol, Outlook can get stuck in various, hard to diagnose, situations.
This is especially problematic as those situations often are caused by issues invisible to the user. Outlook will simply stop synchronizing partially or completely.
Today we deploy an update with two remediable measures.
1. We force various default folders to always be synchronized, because Outlook does not handle the absence of those folders well.
This is visible in the ActiveSync configuration UI in the webclient:
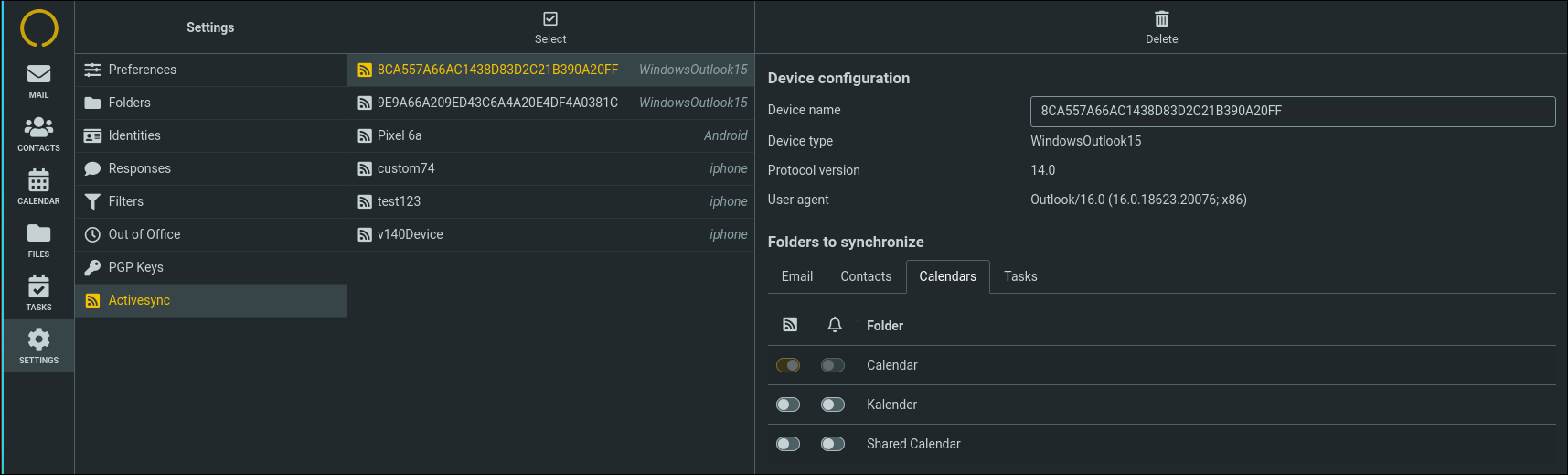
2. We mark devices that are detected to be stuck in a loop as broken. These devices have to be manually reset according to the procedure outlined in the knowledgebase.
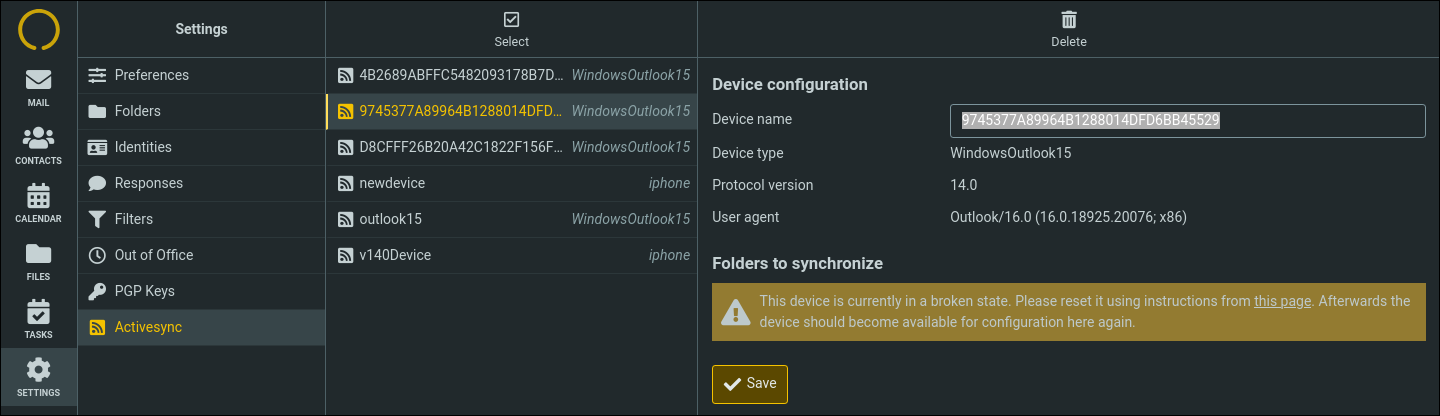
For broken devices Outlook will now report the disconnected state, instead of showing connected while failing to synchronize. This should help to detect this situation and allow you to reset early.
As always, if you have questions or concerns, you are very welcome to contact Support.
Refurbishing Kolab Now – enhancements on our website about to be launched
It is June again – the season of spring cleanup and refurbishment: prefect timing to also enhance the Kolab Now frontpage to give it more structure & clarity to communicate in a clear manner what makes us different and special.
Incident report: 50% of ActiveSync connections failed..
On Sunday 2025-06-15 one of the Kolab now ActiveSync servers were getting overloaded and got stuck on failed jobs. In turn, about 50% of the ActiveSync jobs were failing – leading to some ActiveSync users loosing the connections to Outlook or to their mobile devices.
